O'Reilly: Chapter 1 Exercise 1 - 16
Read through Chapter 1 of the O'Reilly's textbook. Here quickly go through the exercise. These are just my results and might not be the best answers of the questions.
1.
>>> 12 / (4 + 1) 2 >>> from __future__ import division >>> 12 / (4 + 1) 2.4
2.
>>> 26 ** 10 141167095653376 >>> 26 ** 100 3142930641582938830174357788501626427282669988762475256374173175398995908420104023465432599069702289330964075081611719197835869803511992549376L
3.
>>> ['Monty', 'Python'] * 20 ['Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python', 'Monty', 'Python'] >>> import nltk >>> from nltk.book import * *** Introductory Examples for the NLTK Book *** Loading text1, ..., text9 and sent1, ..., sent9 Type the name of the text or sentence to view it. Type: 'texts()' or 'sents()' to list the materials. text1: Moby Dick by Herman Melville 1851 text2: Sense and Sensibility by Jane Austen 1811 text3: The Book of Genesis text4: Inaugural Address Corpus text5: Chat Corpus text6: Monty Python and the Holy Grail text7: Wall Street Journal text8: Personals Corpus text9: The Man Who Was Thursday by G . K . Chesterton 1908 >>> 3 * sent1 ['Call', 'me', 'Ishmael', '.', 'Call', 'me', 'Ishmael', '.', 'Call', 'me', 'Ishmael', '.']
4.
>>> len(set(text2)) 6833 >>> len(text2) 141576
5. Answer: Romance. The number of set(text) and diversity is higher than humour.
How to calculate diversity for review:
>>> len(text2) 141576 >>> len(set(text2)) 6833 >>> len(text3) 44764 >>> len(set(text3)) 2789 >>> def lexical_diversity(text): ... return len(text) / len(set(text)) ... >>> lexical_diversity(text2) 20.719449729255086 >>> lexical_diversity(text3) 16.050197203298673
6.
>>> text2.dispersion_plot(["Elinor", "Marianne", "Edward", "Willoughby"])
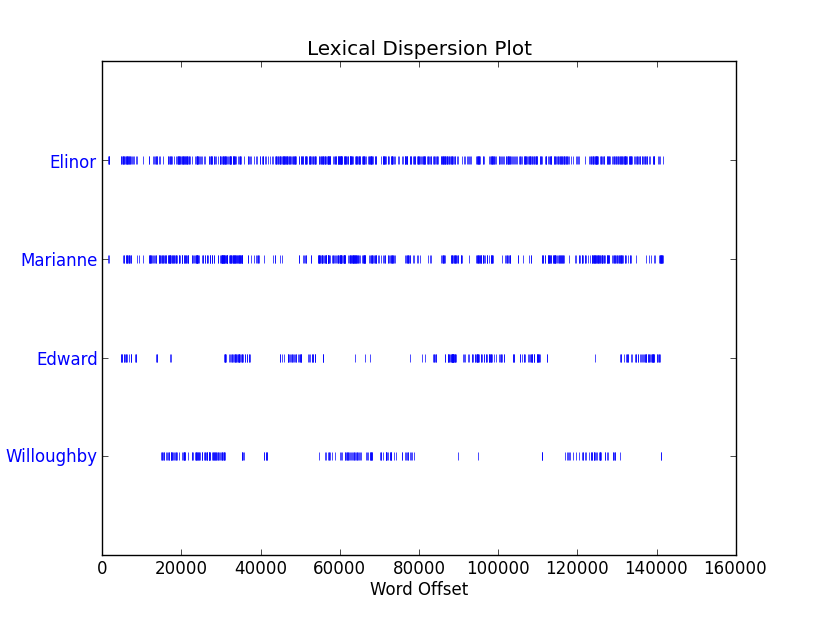
Marianne and Willoughby might be a couple? They are at same scenes more frequently.
7.
>>> text5.collocations() Building collocations list wanna chat; PART JOIN; MODE #14-19teens; JOIN PART; cute.-ass MP3; MP3 player; times .. .; ACTION watches; guys wanna; song lasts; last night; ACTION sits; -...)...- S.M.R.; Lime Player; Player 12%; dont know; lez gurls; long time; gently kisses; Last seen
8.
>>> len(set(text4)) 9754
2 steps are included in this command. First, excluding duplicated words by set(text4) then count number of words.
9.
>>> my_string = 'I love eating!'
>>> my_string
'I love eating!'
>>> print my_string
I love eating!
>>> my_string + my_string
'I love eating!I love eating!'
>>> mystring / 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'mystring' is not defined
>>> my_string * 2
'I love eating!I love eating!'
>>> my_string * 3
'I love eating!I love eating!I love eating!'
>>> (my_string + ' ') * 3
'I love eating! I love eating! I love eating! '
<pre>|
Note: Division (/) does not work for strings.
10.
>>> my_sent = ["Eat", "like", "drinking"] >>> ' '.join(my_sent) 'Eat like drinking' >>> my_sent2 = ' '.join(my_sent) >>> my_sent2 'Eat like drinking' >>> split(my_sent2) Traceback (most recent call last): File "<stdin>", line 1, in <module>; NameError: name 'split' is not defined >>> my_sent2.split() ['Eat', 'like', 'drinking']
11.
>>> phrase1 = ["Apple", "Mac", "iPhone", "iPad"] >>> phrase2 = ["Microsoft", "Windows", "Surface"] >>> len(phrase1 + phrase2) 7 >>> len(phrase1) + len(phrase2) 7
Got same results.
12.
>>> "Monty Python"[6:12] 'Python' >>> ["Monty", "Python"][1] 'Python'
The second one should be more NLP related in general.
13.
>>> sent1 ['Call', 'me', 'Ishmael', '.'] >>> sent1[2][2] 'h' >>> sent1[0][1] 'a'||< The first [] is to get a element of sent1 and the second [] for taking character in the element. <strong>sent1[2][2]</strong> takes 3rd element (as the first element start with[0]) then pick up 3rd character in "Is<strong>h</strong>mael". Therefore the return is '<strong>h</strong>'. <strong>sent[0][1]</strong> to get 2nd character of the first element then '<strong>a</strong>' was returned. 14. 5 & 8 >|python| >>> sent3 ['In', 'the', 'beginning', 'God', 'created', 'the', 'heaven', 'and', 'the', 'earth', '.'] >>> for i in range(len(sent3)): ... if sent3[i] == 'the': ... print i ... 1 5 8
Not so cool. There should be smarter way.
15.
>>> sorted([w for w in text5 if w.startswith("b")]) ['b', 'b', 'b', 'b', 'b', 'b', 'b-day', 'b/c', 'b4', 'b4', 'babay', 'babble', 'babblein', 'babe', 'babe', 'babe', 'babe', 'babe', 'babe', 'babe', 'babe', 'babe', 'babe', 'babe', 'babes', 'babes', 'babes', 'babi', 'babi', 'babies', 'babies', 'babiess', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby', 'baby',....
So many words are duplicated. Should add set() then get better list.
>>> sorted(set([w for w in text5 if w.startswith("b")])) ['b', 'b-day', 'b/c', 'b4', 'babay', 'babble', 'babblein', 'babe', 'babes', 'babi', 'babies', 'babiess', 'baby', 'babycakeses', 'bachelorette', 'back', 'backatchya', 'backfrontsidewaysandallaroundtheworld', 'backroom', 'backup', 'bacl', 'bad', 'bag', 'bagel', 'bagels', 'bahahahaa', 'bak', 'baked', 'balad', 'balance', 'balck', 'ball', 'ballin', 'balls', 'ban', 'band', 'bandito', 'bandsaw', 'banjoes', 'banned', 'baord', 'bar', 'barbie', 'bare', 'barely', 'bares', 'barfights', 'barks', 'barn', 'barrel', 'base', 'bases', 'basically', 'basket', 'battery', 'bay', 'bbbbbyyyyyyyeeeeeeeee', 'bbiam', 'bbl', 'bbs', 'bc', 'be', 'beach', 'beachhhh', 'beam', 'beams', 'beanbag', 'beans', 'bear', 'bears', 'beat', 'beaten', 'beatles', 'beats', 'beattles', 'beautiful', 'because', 'beckley', 'become', 'bed', 'bedford', 'bedroom', 'beeeeehave', 'beeehave', 'been', 'beer', 'before', 'beg', 'begin', 'behave', 'behind', 'bein', 'being', 'beleive', 'believe', 'belive', 'bell', 'belly', 'belong', 'belongings', 'ben', 'bend', 'benz', 'bes', 'beside', 'besides', 'best', 'bet', 'betrayal', 'betta', 'better', 'between', 'beuty', 'bf', 'bi', 'biatch', 'bible', 'biebsa', 'bied', 'big', 'bigest', 'biggest', 'biiiatch', 'bike', 'bikes', 'bikini', 'bio', 'bird', 'birfday', 'birthday', 'bisexual', 'bishes', 'bit', 'bitch', 'bitches', 'bitdh', 'bite', 'bites', 'biyatch', 'biz', 'bj', 'black', 'blade', 'blah', 'blank', 'blankie', 'blazed', 'bleach', 'blech', 'bless', 'blessings', 'blew', 'blind', 'blinks', 'bliss', 'blocking', 'bloe', 'blood', 'blooded', 'bloody', 'blow', 'blowing', 'blowjob', 'blowup', 'blue', 'blueberry', 'bluer', 'blues', 'blunt', 'board', 'bob', 'bodies', 'body', 'boed', 'boght', 'boi', 'boing', 'boinked', 'bois', 'bomb', 'bone', 'boned', 'bones', 'bong', 'boning', 'bonus', 'boo', 'booboo', 'boobs', 'book', 'boom', 'boooooooooooglyyyyyy', 'boost', 'boot', 'bootay', 'booted', 'boots', 'booty', 'border', 'borderline', 'bored', 'boredom', 'boring', 'born', 'born-again', 'bosom', 'boss', 'bossy', 'bot', 'both', 'bother', 'bothering', 'bottle', 'bought', 'bounced', 'bouncer', 'bouncers', 'bound', 'bout', 'bouts', 'bow', 'bowl', 'box', 'boy', 'boyfriend', 'boys', 'bra', 'brad', 'brady', 'brain', 'brakes', 'brass', 'brat', 'brb', 'brbbb', 'bread', 'break', 'breaks', 'breath', 'breathe', 'bred', 'breeding', 'bright', 'brightened', 'bring', 'brings', 'bro', 'broke', 'brooklyn', 'brother', 'brothers', 'brought', 'brown', 'brrrrrrr', 'bruises', 'brunswick', 'brwn', 'btw', 'bucks', 'buddyyyyyy', 'buff', 'buffalo', 'bug', 'bugs', 'buh', 'build', 'builds', 'built', 'bull', 'bulls', 'bum', 'bumber', 'bummer', 'bumped', 'bumper', 'bunch', 'bunny', 'burger', 'burito', 'burned', 'burns', 'burp', 'burpin', 'burps', 'burried', 'burryed', 'bus', 'buses', 'bust', 'busted', 'busy', 'but', 'butt', 'butter', 'butterscotch', 'button', 'buttons', 'buy', 'buying', 'bwahahahahahahahahahaha', 'by', 'byb', 'bye', 'byeee', 'byeeee', 'byeeeeeeee', 'byeeeeeeeeeeeee', 'byes']
16.
>>> range(10, 20) [10, 11, 12, 13, 14, 15, 16, 17, 18, 19] >>> range(10, 20, 2) [10, 12, 14, 16, 18] >>> range(20, 10, -2) [20, 18, 16, 14, 12]